-
먼저, 이 글은 구글 리서치의 "Announcing SyntaxNet: The World’s Most Accurate Parser Goes Open Source"를 개인 공부 목적으로 번역한 것임을 밝힙니다.
주소: https://ai.googleblog.com/2016/05/announcing-syntaxnet-worlds-most.htmlNatural Language Understanding (NLU) systems의 중요한 부분이다.
Parsey McParseface는 강력한 기계 학습 알고리즘 기반으로 구축된다.
그 알고리즘은 자연어의 언어학적 구조를 분석하는 방법을 학습하며, 주어진 문장의 각 언어의 기능적 역할을 설명할 수 있다.
SyntaxNet은 어떻게 작동합니까?
SyntaxNet은 학계에서 syntactic parser로 잘 알려진 프레임워크다.
또한 많은 NLU 시스템의 가장 먼저 사용되는 중요한 컴포넌트이다.문장이 입력으로 주어지면, 각 단어에 그 단어의 통어적 기능(syntactic function)을 설명하는 품사(POS; part-of-speech) 태그를 지정하고 종속성 구문 분석 트리에 표시된 문장 내 단어 간의 통어적 관계(syntactic relationships)를 결정한다.
이러한 문법적 관계는 그 문장의 근본적인 의미와 직접적으로 관계가 있다.
의존 구조 (dependency structures)에서 인코딩된 문법적 관계는 우리가 쉽게 다양한 질문에 대한 답변으로 되돌아갈 수 있다.
(원문: The grammatical relationships encoded in dependency structures allow us to easily recover the answers to various questions)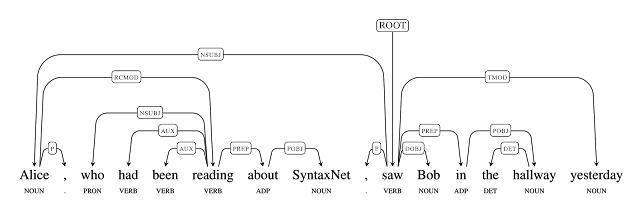
왜 컴퓨터가 파싱을 올바르게 하기 어려울까
파싱(parsing)을 어렵게 만드는 주요 문제 중 하나는 인간의 언어가 놀라운 수준의 모호성(ambiguity)을 보인다는 점이다.
20~30 단어 정도의 적당한 길이의 문장에서도 수백, 수천, 수만 개의 가능한 통어적 구조 (syntactic structures)를 가지는 경우가 흔하다.
자연어 파서(parser)는 어떻게든 이러한 모든 대안을 검색해야하며, 문맥(context)을 고려할 때, 가장 그럴듯한 구조를 찾아야한다.

인간은 모호성을 다루는 놀라운 작업을 하며, 이는 문자가 거의 발견되지 않는 수준이다. 컴퓨터가 이러한 작업을 똑같이 수행하도록 하는 것이 목표이다.
긴 문장 속의 이러한 모호성들과 같이 다중의 모호성(Multiple ambiguity)은 문자에 있는 많은 가능 구조 속 조합들의 폭발을 제공하기 위해 공모한다.
보통 이러한 구조의 대다수는 그럴싸하지 못하다. 하지만, 그것은 그럼에도 불구하고 가능하며, 파서에 의해 어떻게든 제거되야 한다.
SyntaxNet은 이러한 모호성 문제에 신경망을 적용한다. 입력 문장은 왼쪽에서 오른쪽으로 처리되며, 문장의 각 단어로 점진적으로 추가되는 단어간의 종속성이 고려된다.
처리하는 각 지점에서 많은 결정들이 모호성으로 인해 가능해질 것이다. 그리고 신경망은 그들의 타당성을 기반으로 경쟁하는 결정을 위한 스코어를 제공할 것이다.
이러한 이유로, 모델에 빔 서치(Beam search)를 쓰는 것은 매우 중요하다.
각 지점에서 간단하게 가져오는 최선의 결정 대신에, 몇몇의 다른 더 높은 순위의 가설이 고려되는 상황에서만 폐기된다는 가설들을 가지고 다중 부분 가설(multiple partial hypotheses)들이 각 단계에 유지된다.(원문: Instead of simply taking the first-best decision at each point, multiple partial hypotheses are kept at each step, with hypotheses only being discarded when there are several other higher-ranked hypotheses under consideration)
간단한 파서를 생성하는 왼쪽에서 오른쪽으로 진행하는 결정 시퀀스는 하나의 예시는 아래의 문장에 대해 나와있다.
(I bookjed a ticket to Google)
나아가, 논문에서 설명한 것처럼, 학습과 탐색을 긴밀하게 통합하는 것은 가장 높은 예측 정확도를 성취하기 위해 중요하다.
Parsey McParseface 및 기타 SyntaxNet 모델은 Google에서 TensorFlow 프레임워크로 학습한 가장 복잡한 네트워크 중 일부입니다.
구글에서 지원하는 Universal Dependencies Project로부터 몇몇의 데이터가 주어지면, 당신도 당신의 머신에서 파싱 모델을 학습할 수 있다.
Parsey McParseface는 얼마나 정확할까?
무작위로 추출된 영어 뉴스 와이어 문장으로 구성된 표준 벤치마크에서, Parsey McParseface는 우리가 가진 이전의 최첨단 결과물을 넘어서며 94% 이상의 정확도로 단어간의 개별 종속성을 복구한다.
인간의 성과에 대한 문헌에 명시적인 연구는 없지만, 사내 어노테이션(annotation) 프로젝트들에서 이 작업을 위해 숙련된 언어학자들의 96~97%의 사례에 대해 동의 했다는 것을 알고 있다.
이것은 우리가 인간의 성능에 도달하고 있음을 시사하지만, 잘 구성된 텍스트에서만 가능하다. Google WebTreebank (released in 2011)에서 배운 것처럼 웹에서 가져온 문장은 분석하기 훨씬 더 어렵다. Parsey McParseface는 이 데이터에서 90% 이상의 파싱 정확도를 달성했다.
정확도가 완벽하진 않지만, 많은 어플리케이션에서 사용되기에 유용할만큼 충분하다. 이 시점에서 오류의 주요 원인은 실제 지식과 깊은 맥락 추론을 필요로 하는 위에서 언급한 전치사구 부착 모호성(prepositional phrase attachment ambiguity)과 같은 예이다.
기계 학습 (특히 신경망)은 이러한 모호성을 해결하는데 상당한 진전을 이뤘다. 그러나 우리의 작업은 여전히 멈춰있다. 우리는 세계의 지식을 배울 수 있고, 모든 언어와 맥락에서 자연어를 동등하게 이해할 수 있는 방법을 개발하고 싶다.
시작하려면, SyntaxNet 코드를 보고 Parsey McParseface 파서 모델을 다운로드하세요. 즐거운 파싱이 되기를.
추가
q1. 구글의 SyntaxNet은 ambiguity problem을 어떻게 해결했을까a1. SyntaxNet은 모호성 해결을 위해 신경망을 적용했다. 처리하는 각 지점마다 발생하는 결정(아마 결정 트리일 듯)에 타당성을 기준으로 점수를 부여했다. 점수가 부여된 모델에 매 선택의 순간마다 최적우선탐색이 아닌 빔 서치 (Beam serach)를 사용하여 명백한 결격사유가 등장했을 때, 후보군에서 탈락시켜 최적의 모범답안을 찾아냈다.
q2. 자연어 처리 모델에서 비슷한 해결방법을 사용한 경우가 있었나
a2. 워드 벡터를 통해 단어간의 유사도를 계산하여 자연어를 적절하게 해석하고 이용했다.